How Not Picking an Experiment Winner Led to a 227% Increase in Revenue
By now most marketers are familiar with the process of experimentation, identify a hypothesis, design a test that splits the population across one or more variants and select a winning variation based on a success metric. This “winner” has a heavy responsibility – we’re assuming that it confers the improvement in revenue and conversion that we measured during the experiment.
Is this always the case? As marketers we’re often told to look at the scientific community as the gold standard for rigorous experimental methodology. But it’s informative to take a look at where even medical testing has come up short.
For years women have been chronically underrepresented in medical trials, which disproportionately favors males in the testing population. This selection bias in medical testing extends back to pre-clinical stages – the majority of drug development research being done on male-only lab animals.
And this testing bias has had real-world consequences. A 2001 report found that 80% of the FDA-approved drugs pulled from the market for “unacceptable health risks” were found to be more harmful to women than to men. In 2013 the FDA announced revised dosing recommendations of the sleep aid Ambien, after finding that women were susceptible to risks resulting from slower metabolism of the medication.
This is a specific example of the problem of external validity in experimentation which poses a risk even if a randomized experiment is conducted appropriately and it’s possible to infer cause and effect conclusions (internal validity.) If the sampled population does not represent the broader population, then those conclusions are likely to be compromised.
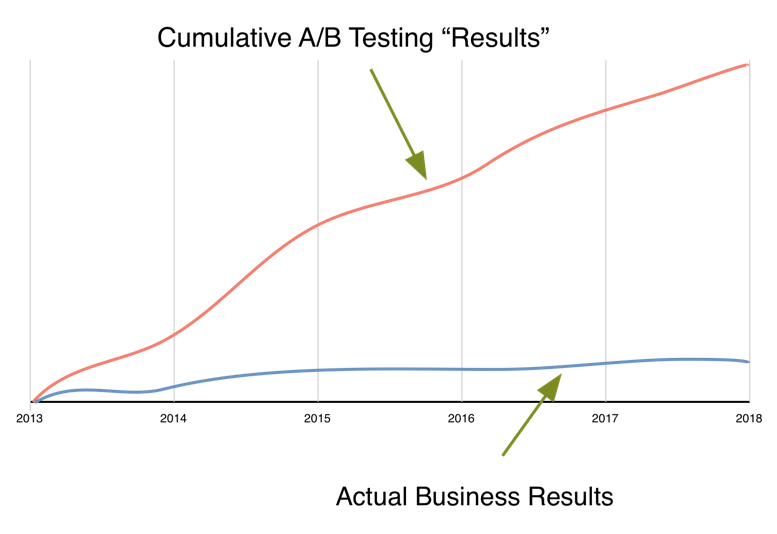
Although they’re unlikely to pose a life-or-death scenario, external validity threats are very real risks to marketing experimentation. That triple digit improvement you saw within the test likely won’t produce the expected return when implemented. Ensuring test validity can be a challenging and resource intensive process, fortunately however it’s possible to decouple your return from many of these external threats entirely.
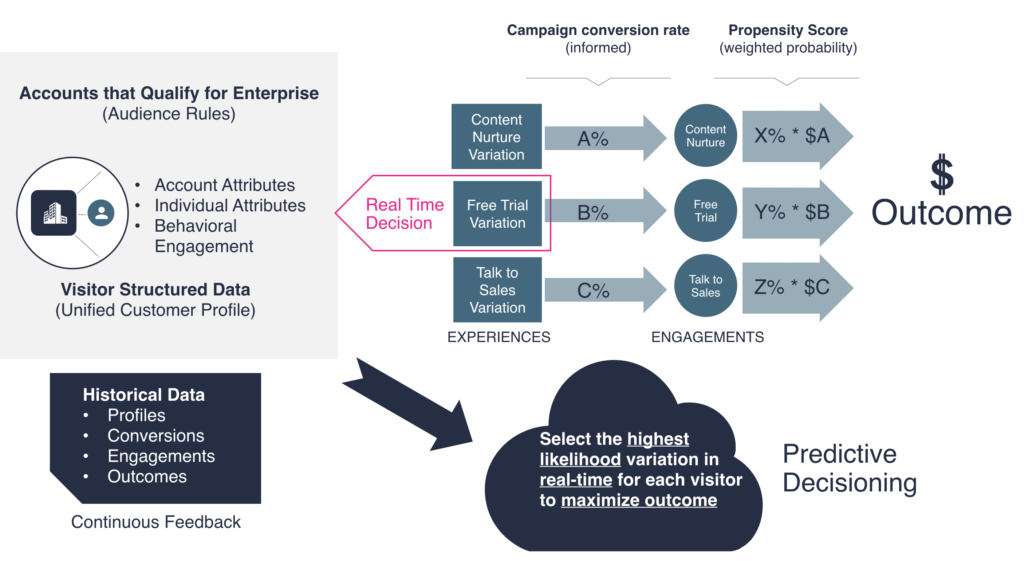
The experiments that you run have to result in better decisions, and ultimately ROI. Further down we’ll look at a situation where an external validity threat in the form of a separate campaign would have invalidated the results of a traditional A/B test. In addition, I’ll show how we were able to adjust and even exploit this external factor using a predictive optimization approach which resulted in a Customer Lifetime Value (LTV) increase of almost 70%.